Some problems with the model US policymakers are using to forecast coronavirus outbreak
Follow @PapersCovidA letter published in the Annals of Internal Medicine urges caution for policy makers relying on IHME’s model.
The TL;DR is captured by a statistician
Yet another important reminder, it doesn't get clearer than this:
— Leontine Alkema (@LeontineAlkema) April 15, 2020
"The IHME projections are based not on transmission dynamics but on a statistical model with no epidemiologic basis."
Fromhttps://t.co/BPO2j5bRvf
You have probably seen this model before, it’s the one that gives graphs such as this
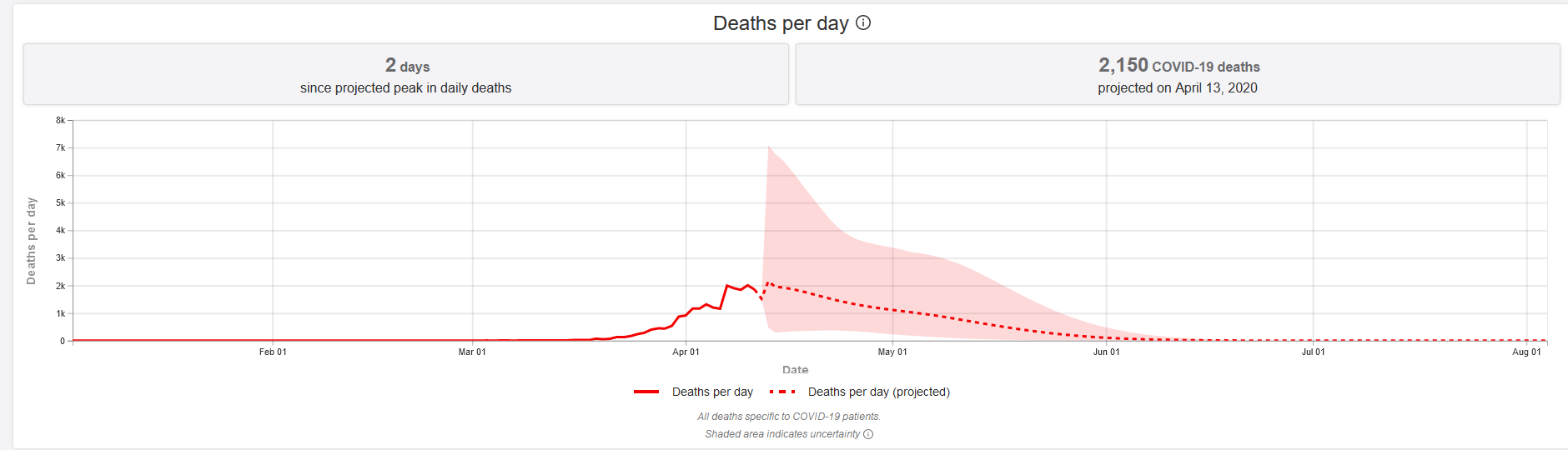
And even if you haven’t, you’ve certainly heard about it. It’s the model that has been quoted by US policymakers for an initial worst case of 1 to 2 million and then a best case of 100-200 thousand.
Here are some problems with the model
First,
The model rests on the likely incorrect assumption that effects of social distancing policies are the same everywhere and that suppression policies will be implemented in all regions and will remain effective throughout.
Second, he model is overly reliant on the reported outcomes in Hubei and South Korea which took very different approaches than places for which the model is being used to make predictions.
Third, is that it is based mostly on reported death counts
death counts can be unreliable and reporting differences occur even within regions. Although Hubei province data represent the most complete mortality curve available, these numbers are suspect
Fourth, the model also has had to shift its predictions wildly in the past and isn’t very transparent about why this is
updated projections already reveal substantial volatility. For New York, the model predicted 10 243 deaths (range, 5167 to 26 444) on 27 March and 15 546 (range, 8016 to 22 255) on 30 March. Given the opaqueness of the model and underlying source data, it is challenging to understand why other regions’ projections also change dramatically. The alignment of past predictions with reality and current predictions should also be reported transparently.
And finally, the model is being quoted in the media without awareness or communication of any of the caveats above.